A data structure can be any organization, management, and storage format of data that allows efficient access and modification. It is a collection of data values, relationships amongst them, and the various functions or operations that can be applied to the data.
Data structures are a foundational concept of programming which is heavily utilized in algorithm design. As such, it is important for any programmer, irrespective of their primary programming language, to have a good understanding of the concept as well as what data structure questions are commonly asked.
Here we cover data structure interview questions that you might expect when applying for a position.
Top Data Structure Interview Questions and Answers
Any programming language interview can have a few or many questions based on data structures. Here are the top data structures and algorithms interview questions with their respective answers.
If you prefer, you may download our Data Structure Interview Questions and Answers PDF.
1. What is a data structure?
A data structure is a convenient way to organize and manipulate data. There are many kinds of data structures and each of them has distinct applications.
For instance, compiler implementations use hash tables for looking up identifiers. Similarly, B-trees are suitable for databases. Data structures are used in Artificial Intelligence, compiler design, database management, graphics, numerical analysis, operating systems, and statistical analysis.
2. How does a linear data structure differ from a non-linear data structure?
If the elements of a data structure form a sequence or a linear list then it is called a linear data structure. Non-linear data structures are those in which the traversal of nodes is done non-linearly.
Arrays, linked lists, stacks, and queues are examples of linear data structures, while graphs and trees are examples of non-linear data structures.
3. What are the applications of data structures?
Some practical applications of data structures are:
- Storing data in a tabular form. For example, the contact details of an individual can be stored in arrays.
- Arrays are widely used in image processing and speech processing.
- Music players and image sliders use linked lists to switch between items.
- A queue is used for job scheduling - the arrangement of data packets for communication.
- A tree is used by the decision tree algorithm in machine learning.
- Technologies like blockchain and cryptography are based on hashing algorithms.
- Matrices are widely used to represent data and plot graphs, and perform statistical analysis.
4. What is the difference between file structure and storage structure?
- File Structure: A hard disk or external device (such as USB), stores data that remains intact till manually deleted. Such a representation of data into secondary or auxiliary memory is called a file structure.
- Storage Structure: In this type of structure, data (variables, constants, etc.) are stored in the main memory, i.e. RAM, and is deleted once the function that uses this data has been completed.
5. What are the various operations that can be performed on a data structure?
The following are the operations that can be performed on a data structure:
- Deletion: Deleting an existing element from the data structure.
- Insertion: Adding a new element to the data structure.
- Searching: Find the location of an element, if it exists, in the data structure.
- Sorting: Arranging elements of the data structure in ascending or descending order for numerical data, and dictionary order for alphanumeric data.
- Traversal: Accessing each element of the data structure once for processing.
6. Explain the postfix expression.
In a postfix expression, the operator is fixed after the operands. Some examples are:
- B++ (i.e. B+B)
- AB+ (i.e. A+B)
- ABC*+ (i.e. A+B*C)
- AB*CD*+ (i.e. A*B + C*D)
7. Which data structures are used for BFS and DFS of a graph?
Breadth-First Search (BFS) of a graph uses a queue. Depth First Search (DFS) of a graph uses a stack, but it can also be implemented using recursion through a function call stack.
Suggested Course
The Data Science Course 2024: Complete Data Science Bootcamp
8. What is a multidimensional array?
If an array has more than two dimensions, it is called a multidimensional array. They are also called an array of arrays. For example, a 3-D array will look like:
int 3darr[10][20][30] – this array can store 10*20*30 elements.
Assigning values
int ndarr[2][3][5] = {{{1,2,4,5},{5,6,7,9}, {6,5,4,3}}, {{1,1,3,4}, {2,3,4,6}, {5,6,7,8}}};
Accessing elements
To access each element, we need three nested loops, say i,j,k, so that we can get the value as ndarr[i][j][k]
9. What is a stack? State some applications.
A stack is a linear data structure that follows either the LIFO (Last In First Out) or FILO (First In Last Out) approach for accessing elements. Push, pop, and peek are the basic operations of a stack.
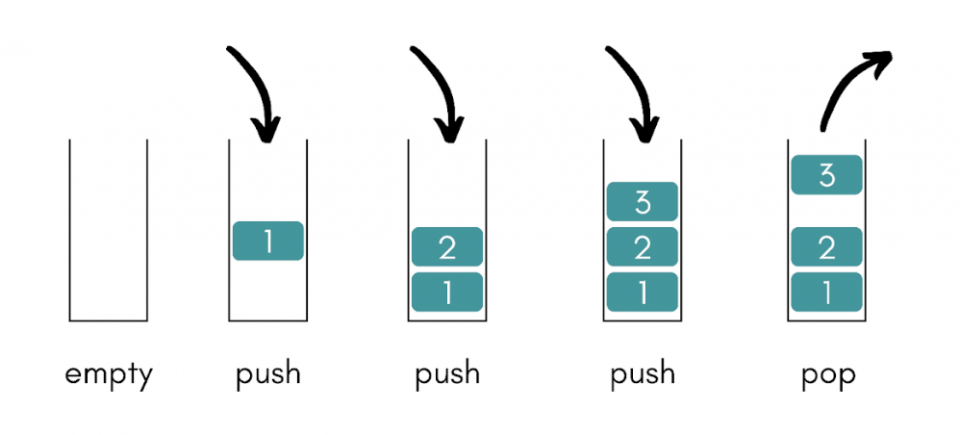
Some applications of a stack are:
- Checking for balanced parentheses in an expression
- The evaluation of a postfix expression
- Implementing two stacks in an array
- Infix to postfix conversion
- Reversing a string
10. What is a queue? How is it different from a stack?
A queue is a form of linear structure that follows the FIFO (First In First Out) approach for accessing elements. Dequeue, enqueue, front, and rear are basic operations on a queue. Like a stack, a queue can be implemented using arrays and linked lists.
In a stack, the item that is most recently added is removed first. Contrary to this, in the case of a queue, the item least recently added is removed first.
11. What is a binary search? When is it best used?
A binary search is an algorithm that starts with searching from the middle element. If the middle element is not the target element then it checks if it should search the lower half or the higher half. The process continues until the target element is found.
The binary search works best when applied to a list with sorted or ordered elements.
12. How do you reference all the elements in a one-dimension array?
We can reference all the elements in a one-dimension array using an indexed loop. The counter runs from 0 to the maximum array size, say n, minus one. All elements of the one-dimension array are referenced in sequence by using the loop counter as the array subscript.
13. What are FIFO and LIFO?
Both FIFO and LIFO are approaches to accessing, storing, and retrieving elements from a data structure. LIFO stands for Last In First Out. In this approach, the most recently stored data is the one to be extracted first.
FIFO stands for First In First Out. With this approach, the data that is stored earliest will be extracted first.
14. What is a linked list?
In a linked list, elements are stored linearly, but the physical placements do not relate to the order in the memory; instead, each element points to the next node. The last one points to a terminator indicating the end of the list. There are many types of linked lists, such as single, double, circular, and multiple. A simple singly linked list can be drawn as:
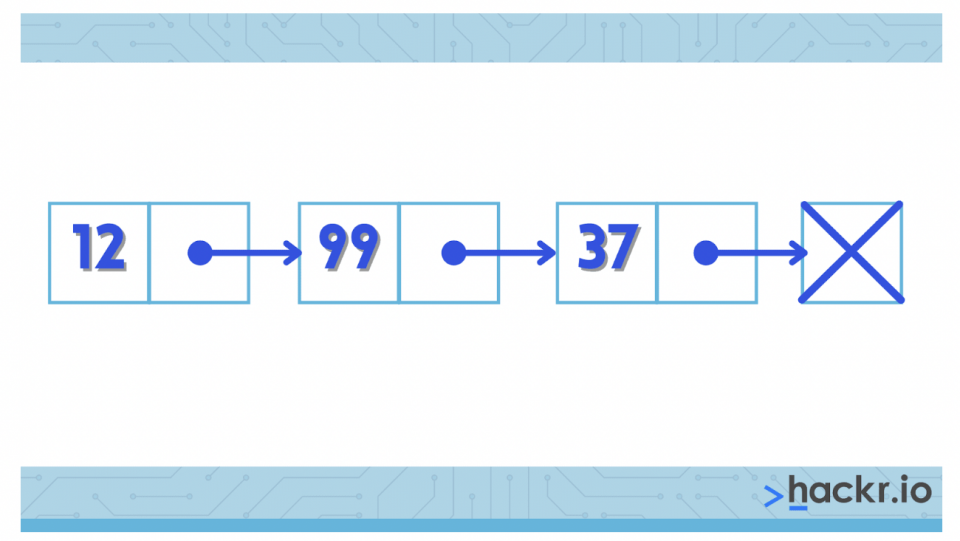
15. How does dynamic memory allocation help in managing data?
Dynamic memory allocation helps in storing simple structured data types. It can also combine separately allocated structured blocks for forming composite structures that contract and expand as required.
16. What is the difference between NULL and VOID?
While NULL is a value, VOID is a data type identifier. A variable assigned with a NULL value represents an empty value. The VOID is used for identifying pointers having no initial size.
17. If you are using the language C to implement the heterogeneous linked list, what pointer type should be used?
We can use void pointers. Unsigned char pointers are another option. This way, we can store any data type in the list. For example:
structa{
structa *next;
s_ize d_size;
}
18. How does Pop differ from Push?
Both push and pop operations pertain to a stack. Data is added to the stack using the push operation, while it is retrieved using the pop operation.
19. How does variable declaration affect memory allocation?
The total amount of memory to be allocated or reserved in the case of a variable declaration depends on the data type used. For instance, declaring an integer type variable reserves 4 bytes of memory space while declaring a double variable reserves 8 bytes of the available memory.
20. Write the syntax in C to create a node in the singly linked list.
newNode = Node(data); //creates a new node.
21. What is data abstraction?
Data abstraction helps in dividing complex data problems into smaller, easy-to-manage parts. It starts with specifying all the involved data objects and the various operations to be performed without worrying too much about the way data is stored.
22. Write a C program to insert a node in a circular singly list at the beginning.
In a circular linked list, the last pointer points to the head (first node). For this, we use an external pointer that points to the last node, and the last->next points to the first node. We take the last node pointer because it saves us from traversing the entire list while inserting a node in the beginning or end.
Program steps
- Create a node N
- N->next = last->next
- last->next = N
Code:
struct Node *addBeginning(struct Node *last, int data)
{
/*check if list empty, if so create a node, else proceed as below*/
// dynamically create a node
struct Node *N
= (struct Node *)malloc(sizeof(struct Node));
// Assign the data.
N -> data = data;
// last pointer becomes the first node
N -> next = last -> next;
last -> next = N;
return last;
}
23. How do you insert a new item in a binary search tree?
As a binary search tree doesn’t allow for duplicates, the new item to be inserted must be unique. Assuming it is, we will proceed with checking whether the tree is empty or not. If it is empty, then the new item will be inserted into the root node.
However, if the tree is non-empty, then we will refer to the key of the new item. When it is smaller than the root item’s key, the new item will be added to the left subtree. If the new item’s key is bigger than the root item’s key, then the new item is inserted into the right subtree.
24. How does the selection sort work on an array?
The selection sort begins with finding the smallest element. It is switched with the element present at subscript 0. Next, the smallest element in the remaining subarray is located and switched with the element residing in the subscript 1.
The aforementioned process is repeated until the biggest element is placed at the subscript n-1, where n represents the size of the given array.
25. Write the pseudocode to perform in-order traversal on a binary tree.
In-order traversal is a depth-first traversal. The method is called recursively to perform traversal on a binary tree. The code is as follows:
structbtnode
{
structbtnode *left;
structbtnode *right;
}
*root = NULL, *temp = NULL;
voidinorder(struct btnode *temp)
{
if (root == NULL)
{
printf("Root is empty");
return;
}
if (temp->left != NULL)
inorder(temp->left);
if (temp->right != NULL)
inorder(t->right);
}26. Write the recursive C function to count the number of nodes present in a binary tree.
staticint counter = 0;
intcountnodes(struct node *root)
{
if(root != NULL)
{
countnodes(root->left);
counter++;
countnodes(root->right);
}
return counter;
}27. Write a recursive C function to calculate the height of a binary tree.
To find the height using recursion, we find the maximum of the height of subtrees on the left and right sides and then add it with the root.
staticint counter = 0;
intcountnodes(struct node *root)
{
if(root != NULL)
{
countnodes(root->left);
counter++;
countnodes(root->right);
}
return counter;
}28. How is memory affected by signed and unsigned numbers?
For signed numbers, the first bit is reserved for indicating whether the number is positive or negative. Hence, it has one bit less for storing the value. Unlike signed numbers, unsigned numbers have all the bits available for storing the number.
The effect of the aforementioned can be seen in the value range available to signed and unsigned numbers. While an unsigned 8-bit number can have a range of 0 to 255, an 8-bit signed number has a range varying from -128 to 127.
29. Do all declaration statements result in a fixed memory reservation?
Except for pointers, all declaration statements result in a fixed memory reservation. Instead of allocating memory for storing data, a pointer declaration results in allocating memory for storing the address of the pointer variable.
For pointers, actual memory allocation for the data happens during runtime.
30. How does an array differ from a stack?
A stack follows the LIFO approach. This means that data manipulation follows a specific sequence where the latest data element is the one to be retrieved first.
Unlike a stack, an array doesn’t follow any particular sequence for adding or retrieving data. Adding or retrieving an element in an array is done by referring to the array index.
31. What is an AVL tree?
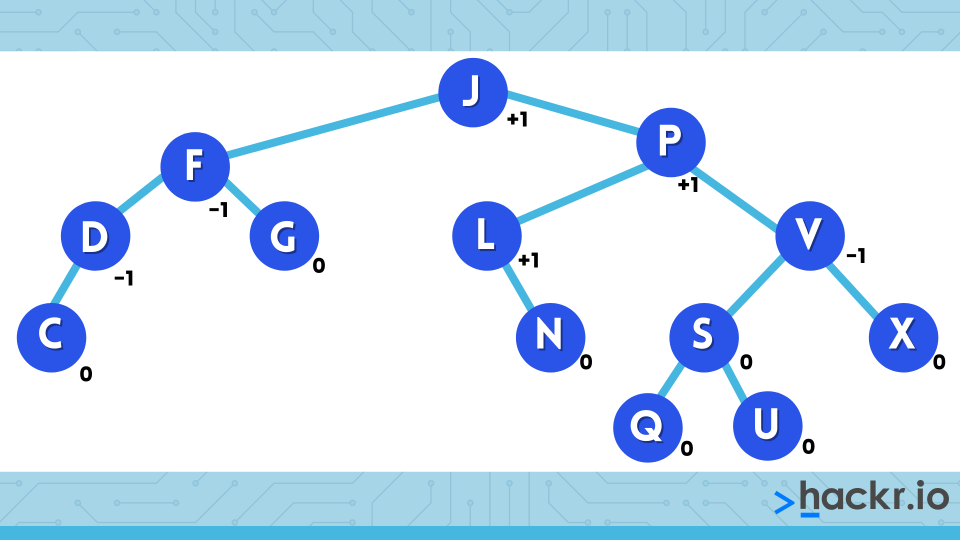
An AVL tree is a type of Binary Search Tree which is always in a partially-balanced state. The measure of the balance is given by the difference of the heights of the subtrees from the root node of the AVL tree.
32. How does an array differ from a linked list?
The following are the differences between an array and a linked list:
- Additional Memory: For each element belonging to a linked list, extra memory space is required for storing the pointer. Arrays have no such requirement.
- Cache: In comparison to linked lists, arrays have better cache locality, which can significantly enhance performance in various scenarios.
- Insertion and Deletion: It is easy to add or delete elements in a linked list. Inserting and deleting elements for an array is comparatively expensive.
- Random Access: Linked lists do not allow random access, while arrays do.
- Size: While the size of an array is fixed, the size of a linked list is dynamic.
33. What are Infix, Prefix, and Postfix notations?
- Infix Notation: Operators are written between the operands. This is the standard way of writing expressions. For example: A * (B + C) / D
- Postfix Notation/Reverse Polish Notation: Operators are written after the operands, hence the name. For example: A B C + * D /
- Prefix Notation/Polish Notation: Operators are written before the operands. / * A + B C D is the prefix notation equivalent of the aforementioned postfix notation example.
34. What is a linked list and what are the various types?
In a linked list, each element is a distinct object. Like arrays, linked lists are a linear type of data structure. In addition to data, every element of a linked list has a reference to the next element. The various types of linked lists are:
- Singly linked list: Each node stores the address or reference of the next node in the linked list, except for the last node that stores NULL.
- Doubly linked list: Each node keeps two references. One point to the next node and the other points to the previous node.
- Circular linked list: In this type of linked list, all nodes are connected to form a circle. There is no NULL at the end. A circular linked list can either be a single circular linked list or a double circular linked list.
35. How will you implement a stack using queue and vice-versa?
It is possible to implement a stack using two queues. There are two options: either to make the push operation costly or the pop operation costly.
A queue can also be implemented with two stacks. There are two options: either to make the enQueue operation costly or the deQueue operation costly.
36. Which data structures are used for implementing LRU cache?
By organizing items in order of use, a Least Recently Used or LRU cache allows quick identification of an item that hasn’t been put to use for the longest time. There are two data structures are used for implementing an LRU cache:
- Queue: Implemented using a doubly-linked list. The maximum size of the queue is determined by the total number of frames available, i.e. the cache size. While the most recently used pages will be near the rear end of the queue, the least recently used pages will be near the queue’s front end.
- Hashmap: This has the page number as the key along with the address of the corresponding queue node as the value.
37. What are the various approaches for developing algorithms?
There are 3 main approaches to developing algorithms:
- Divide and Conquer: Involves dividing the entire problem into a number of subproblems and then solving each of them independently.
- Dynamic Programming: Identical to the divide and conquer approach with the exception that all subproblems are solved together
- Greedy Approach: Finds a solution by choosing the next best option.
38. State some examples of both greedy and divide and conquer algorithms.
Examples of algorithms that follow the greedy approach are:
- Dijkstra’s Minimum Spanning Tree
- Graph – Map Coloring
- Graph – Vertex Cover
- Job Scheduling Problem
- Knapsack Problem
- Kruskal’s Minimal Spanning Tree
- Prim’s Minimal Spanning Tree
- Travelling Salesman
Examples of the divide and conquer approach are:
- Binary Search
- Closest Pair (or Points)
- Merge Sort
- Quick Sort
- Strassen’s Matrix Multiplication
39. How does insertion sort differ from selection sort?
Both insertion and selection approaches maintain two sub-lists, sorted and unsorted. Each takes one element from the unsorted sub-list and places it into the sorted sub-list. The distinction between the two sorting processes lies in the treatment of the current element.
Insertion sort takes the current element and places it in the sorted sublist at the appropriate location. Selection sort searches for the minimum value in the unsorted sub-list and replaces the same with the present element.
40. What do you understand by shell sort?
The shell sort can be understood as a variant of the insertion sort. The approach divides the entire list into smaller sub-lists based on some gap variable. Each sub-list is then sorted using insertion sort.
41. Can you explain tree traversal?
The process for visiting all the nodes of a tree is called tree traversal. It always starts from the root node and there are three ways of doing it:
- In-order Traversal
- Pre-order Traversal
- Post-order Traversal
42. What is a spanning tree? What is the maximum number of spanning trees a graph can have?
A spanning tree is a subset of a graph that has all the vertices but with the minimum possible number of edges. A spanning tree cannot be disconnected and does not have cycles.
The maximum number of spanning trees that a graph can have depends on how many connections there are. A complete undirected graph with n number of nodes can have a maximum of n-1 number of spanning trees.
43. How does Kruskal's Algorithm work?
Kruskal’s algorithm treats a graph as a forest and each node in it as an individual tree. A tree connects to another tree only if it:
- Has the least cost among all the available options
- Does not violate MST properties
44. What is a heap?
A heap is a special balanced binary tree in which the root node key is compared with its children and arranged accordingly. It can be of two types:
- Min-Heap: The parent node has a key value less than its children.
- Max-Heap: The parent node has a key value greater than its children.
45. What is recursion?
The ability to allow a function or module to call itself is called recursion. Either a function f calls itself directly or calls another function ‘g’ that in turn calls the function ‘f. The function f is known as the recursive function and it follows recursive properties, which are:
- Base criteria: Where the recursive function stops calling itself.
- Progressive approach: Where the recursive function tries to meet the base criteria in each iteration.
46. What is the Tower of Hanoi problem?
The Tower of Hanoi is a mathematical puzzle that comprises three towers (or pegs) and more than one ring. Each ring is of varying size and stacked upon one another such that the larger one is beneath the smaller one.
The goal of the Tower of Hanoi problem is to move the tower of the disk from one peg to another without breaking the properties.
47. How do the BFS (Breadth-First Search) and DFS (Depth First Search) algorithms work?
The BFS algorithm traverses a graph in the breadthwards motion. It uses a queue to remember the next vertex for starting a search when a dead end occurs in any iteration.
A DFS algorithm traverses a graph in the depthward motion. It uses a stack for remembering the next vertex to start a search when coming across a dead end in an iteration.
48. What do you understand by hashing?
The technique of converting a range of key values into a range of indexes of an array is known as hashing. It is possible to create associative data storage using hash tables where data indices can be found by providing the corresponding key values.
49. What is a Minimum Spanning Tree? How does Prim’s algorithm find it?
An MST or Minimum Spanning Tree is a spanning tree in a weighted graph that has the minimum weight of all the possible spanning trees. Each node is treated as a single tree by Prim’s algorithm while adding new nodes to the spanning tree from the available graph.
50. What is the interpolation search technique?
The interpolation search technique is an enhanced variant of binary search. It works on the probing position of the required value.
51. How do you check if the given Binary Tree is BST or not?
Simply perform an in order traversal of the given binary tree while keeping track of the previous key value. If the current key value is greater, then continue, otherwise return false. The binary tree is BST if the in order traversal of the binary tree is sorted.
Conclusion
That sums up our list of the top DS and algo interview questions. These DS interview questions are also helpful in other programming interviews.
Download our Data Structure Interview Questions and Answers PDF to study these questions whenever you like.
If you’re looking to improve your data structure knowledge, try the best data structure tutorials.
These interview questions on data structures are essential for any programming interview, so don’t ignore them.
Some of them are basic data structure interview questions, while others are data interview questions for experienced developers. Either way, they're all important concepts. Good luck!
FAQs
What data structures are asked in interviews?
You’ll be asked about stacks, queues, arrays, linked lists, heaps and trees in your dsa interview questions. Your interviewer will test you on all of them, so don’t leave out any data structure.
What is DS and why is it required?
A data structure is a collection of data stored in a particular way that makes it easy to manage and manipulate. With good data structure usage, you can efficiently traverse and abstract data, as well as reuse it. This is why data structure interview questions are present for almost every software development role.
What is the difference between data structures and algorithms?
A data structure allows you to store data in an efficient and organized manner. An algorithm is a sequence of steps that tell how to solve a particular problem.
What are the 3 characteristics of data structures?
The 3 characteristics of data structures are whether they are linear or nonlinear; whether they are homogenous or heterogenous; and whether they are static or dynamic. These properties determine what data structure it is. For example, an array is linear and a graph is nonlinear.
People are also reading:
- Python Interview Questions and Answers
- AngularJS Interview Questions & Answers
- C++ Interview Questions and Answers
- PHP Interview Questions and Answers
- Top Bootstrap Interview Questions and Answers
- Top Android Interview Questions and Answers
- Top Java Interview Questions and Answers
