Are you wondering which framework to use for big data? This Hadoop vs Spark comparison will make it clear which one is best for your needs.
The internet has resulted in huge volumes of data being continuously generated – which is popularly known as Big Data. This data, in both structured and unstructured forms, is generated from primary sources such as social networks, the Internet of Things (IoT), and traditional transactional business.
Distributed computing, which facilitated a new generation of data management of Big Data, is a revolutionary innovation in hardware and software technology. Distributed data processing facilitates the storage, processing, and access of this high velocity, large volume, and a wide variety of data.
With distributed computing taking the front seat in the Big Data ecosystem, two powerful products —Apache Hadoop and Spark — have gained significant importance. The life of Big Data management professionals became a lot easier with Hadoop and Spark. But why and how?
Let’s take a look at what Hadoop and Spark are, the key difference between Hadoop and Spark, and which is better in head-to-head comparisons.
Hadoop vs Spark: Head to Head Comparison
Here’s a table that summarizes the differences between Hadoop and Spark, as well as some similarities.
|
Feature |
Hadoop |
Spark |
|
Open Source |
Yes |
Yes |
|
Fault Tolerance |
Yes |
Yes |
|
Data Integration |
Yes |
Yes |
|
Speed |
Low performance |
Higher performance (100x faster) |
|
Ease of Use |
Lengthy code, slow development cycle |
Faster development cycle |
|
Application |
Batch data processing |
Real-time and batch data processing |
|
Latency |
High |
Low |
|
Developer community support |
Yes |
Yes |
|
Cost |
Lower TCO |
Higher TCO |
|
Memory consumption |
Disk-based |
RAM-based |
What is the Hadoop Framework?
The Apache Hadoop software library is a framework for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from a single server to thousands of machines, each offering local computation and storage.
Rather than relying on hardware to deliver high availability, the framework by itself is designed to detect and handle failures at the application layer. In simple terms, Hadoop delivers a high distributed processing service on top of a cluster of computers.
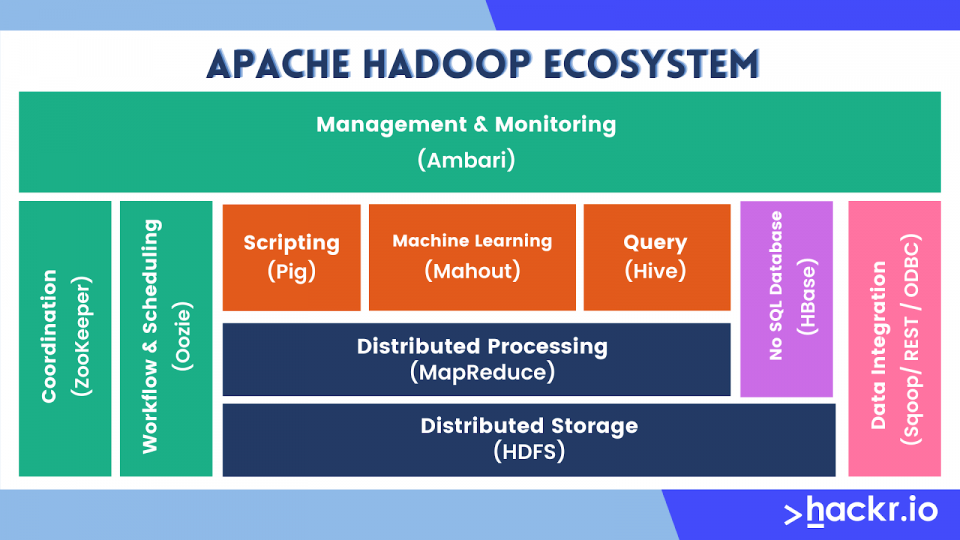
The following are the main Hadoop components:
- Hadoop Common: The common utilities that support other Hadoop modules
- Hadoop Distributed File System (HDFS™): The primary data storage used by Hadoop applications. It is a distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets
- Hadoop Ozone: An object store for Hadoop
- Hadoop Submarine: A machine learning engine for Hadoop
What is the Spark Framework?
Apache Spark is a general-purpose distributed data processing framework where the core engine is suitable for use in a wide range of computing circumstances. On top of the Spark core, there are libraries for SQL, machine learning, graph computation, and stream processing, which can be used together in an application. Resilient Distributed Dataset (RDD) is a fundamental data structure of Spark.

Programming languages supported by Spark include Java, Python, Scala, and R. Application developers and data scientists incorporate Spark into their applications to rapidly query, analyze, and transform data at scale. Tasks most frequently associated with Spark include ETL and SQL batch jobs across large data sets, processing of streaming data from sensors, IoT, or financial systems, and machine learning tasks.
Both are from the Apache product rack. So what paved the way for Apache Spark? Apache Hadoop MapReduce is an extremely famous and widely used execution engine. However, users have consistently complained about the high latency problem with Hadoop MapReduce, stating that the batch mode response for these real-time applications is slow when it comes to processing and analyzing data.
This led to Spark, a successor system that is more powerful and flexible than Hadoop MapReduce.
Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud. It can access a diverse set of data sources, including HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of others
Is Hadoop Better than Spark?
These two work in tandem, so the question of whether Hadoop is better than Spark is somewhat moot. Most of the time, Spark will run on a Hadoop cluster.
However, there are certain instances when you may want to explicitly choose one over the other. For example, if there’s low memory or just an older cluster in general, you may want to choose Hadoop.
Are Spark and Hadoop the Same?
No, they are not, even though they are both big data frameworks and though Spark falls under Hadoop.
Hadoop lets you manage your big data through distributed computing across a cluster of computers. Spark helps you process that data across those computers.
Is Spark Replacing Hadoop?
No, but Spark is finding more use in the industry as it replaces Hadoop’s MapReduce function. Spark runs on top of Hadoop and both have a specific purpose, and they achieve different objectives with their own levels of success.
Why is Spark Faster Than Hadoop?
Spark is theoretically 100 times faster in memory and 10 times faster on disk. It is faster than Hadoop’s MapReduce because it does the processing in RAM, which reduces the read-write operation.
Is Hadoop Required for Spark?
TheSparkdocumentation says that Spark can run without Hadoop. You may run it as a standalone mode without any resource manager. But if you want to run in a multi-node setup, you need a resource manager like YARN or Mesos and a distributed file system like HDFS or S3.
Hadoop vs Spark: Which is Better?
Now that we know the fundamentals of Hadoop and Spark, let’s look at which outperforms the other in various aspects.
1. Open Source - Tie
Both Hadoop and Spark are Apache products and are open-source software for reliable scalable distributed computing.
2. Fault Tolerance - Tie
Fault refers to failure, and both Hadoop and Spark are fault-tolerant. Hadoop systems function properly even after a node in the cluster fails. Fault tolerance is mainly achieved using data replication and Heartbeat messages. RDDs are the building blocks of Apache Spark and are what provide fault tolerance in it.
3. Data integration- Tie
Data produced by different systems across a business is rarely clean or consistent enough to simply and easily be combined for reporting or analysis. Extract, transform, and load (ETL) processes are often used to pull data from different systems, clean and standardize it, and then load it into a separate system for analysis.
Both Spark and Hadoop are used to reduce the cost and time required for this ETL process.
4. Speed - Spark Wins
Spark runs workloads up to 100 times faster than Hadoop. Apache Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine. Spark is designed for speed, operating both in memory and on disk.
A classic comparison on Speed is the fact that the Data bricks team was able to process 100 terabytes of data stored on solid-state drives in just 23 minutes on one-tenth of the machines. The previous winner took 72 minutes using Hadoop and a different cluster configuration.
However, if Spark is running on YARN with other shared services, performance might degrade and cause RAM overhead memory leaks. For this reason, if a user has a use case of batch processing, Hadoop has been found to be a more efficient system.
5. Ease of Use - Spark Wins
Hadoop MapReduce code is comparatively lengthy. In Spark, you can write applications quickly in Java, Scala, Python, R, and SQL. Spark offers over 80 high-level operators that make it easy to build parallel applications, and you can use it interactively from the Scala, Python, R, and SQL shells.
Spark’s capabilities are accessible via a set of rich APIs, all designed specifically for interacting quickly and easily with data at scale. These APIs are well-documented and structured in a way that makes it straightforward for data scientists and application developers to quickly put Spark to work.
6. General usage - Spark Wins
In the case of Hadoop MapReduce, you can only process a batch of stored data. But with Spark, it is possible to modify the data in real-time through Spark Streaming as well.
With Spark Streaming, you can pass data through various software functions - for instance, performing data analytics as and when it is collected. Developers can also make use of Apache Spark for graph processing, which maps the relationships in data amongst various entities such as people and objects. Organizations can make use of Spark with predefined machine learning libraries so that machine learning can be performed on the data that is stored in different Hadoop clusters.
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
7. Latency - Spark Wins
Hadoop is a high latency computing framework that does not have an interactive mode, while Spark is a low latency framework that can process data interactively.
8. Support - Tie
Being open-source, both Hadoop and Spark have plenty of support. The Apache Spark community is large, active, and international.
A growing set of commercial providers, including Databricks, IBM, and all of the main Hadoop vendors, deliver comprehensive support for Spark-based solutions.
The top vendors offering Big Data Hadoop solutions are Cloudera, Hortonworks, Amazon Web Services Elastic MapReduce, Microsoft, MapR, and IBM InfoSphere Insights.
9. Costs - Hadoop Wins
Hadoop and Spark are both Apache open-source projects, so they’re free. The only costs that arise are those associated with the infrastructure. Both products are designed in such a way that they can run on commodity hardware with low TCO (Total Cost of Ownership). However, Spark’s costs are still higher.
10. Memory Consumption - Tie
Storage and processing in Hadoop are disk-based and Hadoop uses the standard amount of memory. With Hadoop, we need a lot of disk space as well as faster disks. Hadoop also requires multiple systems to distribute the disk I/O.
Due to Apache Spark’s in-memory processing, it requires a lot of memory. As multiple units of RAM is relatively expensive, the Spark system incurs a higher cost.
In other words, Spark may be faster, but it will incur higher costs. This is the tradeoff.
The Ultimate Hands-On Hadoop: Tame your Big Data!
Hadoop and Spark are Both Essential for Big Data
So, which is better: Spark or Hadoop?
The truth is, that Hadoop and Spark are not mutually exclusive and can work together. Real-time and faster data processing in Hadoop is not possible without Spark, and the latter doesn’t need a Hadoop cluster to work.
On the other hand, Spark doesn't have a file system for distributed storage, but it can read and process data from other file systems — HDFS, for example. However, there are a lot of advantages to running Spark on top of Hadoop (HDFS + YARN), but it’s not mandatory.
Current trends and reports from user feedback favor the in-memory technique, which means Apache Spark is often the preferred choice.
However, it isn’t so black and white that you will choose one over the other. If you’re going to learn frameworks for big data, you’ll want to learn both.
People are also Reading:
