






The data science field is growing bigger by the day. As such, there are plenty of opportunities for those interested in pursuing a data scientist career. We won’t go into detail about it here, but if you are just starting out with data science, read about how to become a data scientist first.
If you already know the ropes, then it’s time to move on to data science interview questions, so you can nab that dream role. After some general questions about what a data science interview is like, we list beginner and technical data science interview questions and answers. Use these to aid your preparation.
How Do I Prepare for a Data Science Interview?
As you would for any other technical interview — make sure that you’ve got the basics down, and can execute ideas in code. Of course, you should also present a good resume and be prepared to summarize past experiences.
On a more general note, you should also research the company and the specific role you’re applying for. You want to ask questions about the software and the company itself, as it serves to highlight your enthusiasm for the role. It may also be worth looking at reviews on Glassdoor to get a sense of the company and past employees’ experiences.
Are Data Science Interviews Tough?
Data science interviews are not necessarily tougher or easier than other interviews. This is a subjective question, so there is no unequivocal answer. If you've got a good grasp of the fundamentals, can thoroughly and clearly explain any projects you’ve worked on, and can execute technical concepts, you will do fine.
Do Data Scientists Have Coding Interviews?
Yes, you will be likely asked to code during a data science interview. However, the chances are lower than what you might expect for a typical software development role.
Usually, the coding questions relate to data manipulation or SQL knowledge, but you may also face questions related to algorithms, programming practices, and data structures.
Data scientist interviews for roles at tech firms and those that focus on machine learning tend to involve coding questions.
Data Science Interview Questions for Beginners
1. What are the differences between Supervised and Unsupervised Learning?
Supervised learning is a type of machine learning where a function is inferred from labeled training data. The training data contains a set of training examples.
Unsupervised learning, on the other hand, is when inferences are drawn from datasets containing input data without labeled responses.
The following are the various other differences between the two types of machine learning:
|
Supervised Learning |
Unsupervised Learning |
|
|
Algorithms Used |
Decision Trees, K-nearest Neighbor algorithm, Neural Networks, Regression, and Support Vector Machines |
Anomaly Detection, Clustering, Latent Variable Models, and Neural Networks |
|
Problems used for |
Classification and regression |
Classification, dimension reduction, and density estimation |
|
Uses |
Prediction |
Analysis |
We’ve already written about the difference between Supervised Learning vs Unsupervised Learning in detail, so check that out for more info.
2. What is Selection Bias and what are the various types?
Selection bias is typically associated with research that doesn’t have a random selection of participants. It is a type of error that occurs when a researcher decides who is going to be studied. On some occasions, selection bias is also referred to as the selection effect.
In other words, selection bias is a distortion of statistical analysis that results from the sample collecting method. When selection bias is not taken into account, some conclusions made by a research study might not be accurate.
The following are the various types of selection bias:
- Sampling Bias: A systematic error resulting due to a non-random sample of a populace causing certain members of the same to be less likely to be included than others results in a biased sample
- Time Interval: A trial might end at an extreme value, usually due to ethical reasons, but the extreme value is most likely to be reached by the variable with the most variance, even though all variables have a similar mean
- Data: Results when specific data subsets are selected for supporting a conclusion or rejection of bad data arbitrarily
- Attrition: Caused due to attrition, i.e. loss of participants, discounting trial subjects or tests that didn’t run to completion
3. What is the goal of A/B Testing?
A/B Testing is a statistical hypothesis testing meant for a randomized experiment with two variables, A and B. The goal of A/B Testing is to maximize the likelihood of an outcome of some interest by identifying any changes to a webpage.
A highly reliable method for finding out the best online marketing and promotional strategies for a business, A/B Testing can be employed for testing everything, ranging from sales emails to search ads and website copy.
4. Between Python and R, which one would you pick for text analytics, and why?
For text analytics, Python will gain an upper hand over R due for the following reasons:
- The Pandas library in Python offers easy-to-use data structures as well as high-performance data analysis tools
- Python has a faster performance for all types of text analytics
Learn more about R vs Python here.
5. What is the purpose of data cleaning in data analysis?
Data cleaning can be a daunting task due to the fact that as the number of data sources grows, the time required for cleaning the data increases at an exponential rate.
This is due to the vast volume of data generated by additional sources. Data cleaning can solely take up to 80% of the total time required for carrying out a data analysis task.
Nevertheless, there are several reasons for using data cleaning in data analysis. Two of the most important ones are:
- Cleaning data from different sources helps transform the data into a format that is easy to work with
- Data cleaning increases the accuracy of a machine learning model
6. Can you compare the validation set with the test set?
A validation set is part of the training set used for parameter selection. It helps avoid overfitting the machine learning model being developed.
A test set is meant for evaluating or testing the performance of a trained machine learning model.
7. What are linear regression and logistic regression?
Linear regression is a form of statistical technique in which the score of some variable Y is predicted on the basis of the score of a second variable X, referred to as the predictor variable. The Y variable is known as the criterion variable.
Also known as the logit model, logistic regression is a statistical technique for predicting the binary outcome from a linear combination of predictor variables.
8. Explain Recommender Systems and state an application.
Recommender Systems is a subclass of information filtering systems, meant for predicting the preferences or ratings awarded by a user to some product.
An application of a recommender system is the product recommendations section in Amazon. This section contains items based on the user’s search history and past orders.
9. What are the steps involved in an analytics project?
The following are the numerous steps involved in an analytics project:
- Understanding the business problem
- Exploring the data and understanding it
- Preparing the data for modeling by means of detecting outlier values, transforming variables, treating missing values, et cetera
- Running the model and analyzing the result for making appropriate changes or modifications to the model (an iterative step that repeats until the best possible outcome is reached)
- Validating the model using a new dataset
- Implementing the model and tracking the result for analyzing the performance of the same
10. What is Deep Learning?
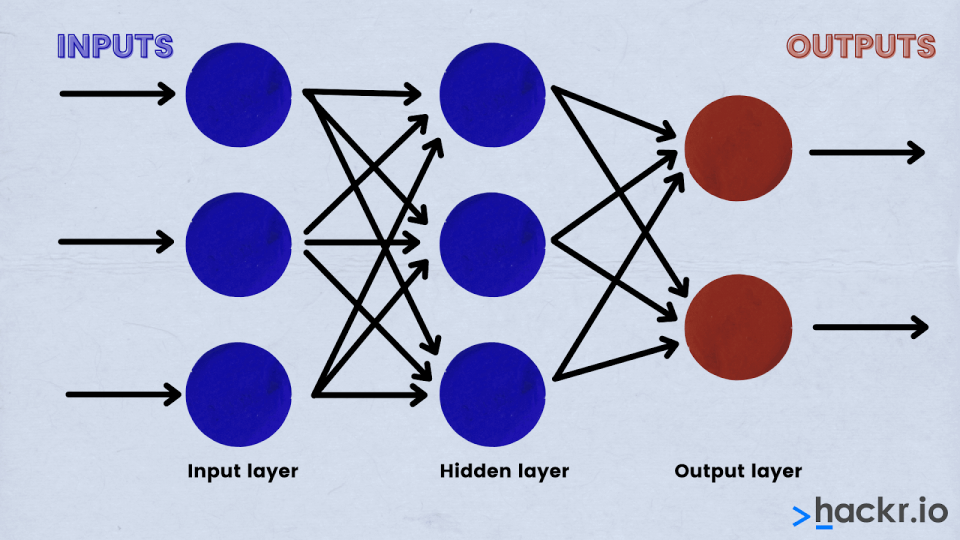
Deep Learning is a paradigm of machine learning that resembles, to a certain extent, the functioning of the human brain. It is a neural network method based on convolutional neural networks (CNN).
Deep learning has a wide array of uses, ranging from social network filtering to medical image analysis and speech recognition. Although Deep Learning has existed for a long time, it’s only recently gained worldwide exposure. This is mainly due to:
- An increase in the amount of data generation
- The growth in hardware resources required for running Deep Learning models
Caffe, Chainer, Keras, Microsoft Cognitive Toolkit, Pytorch, and TensorFlow are some of the most popular Deep Learning frameworks.
11. What is Gradient Descent?
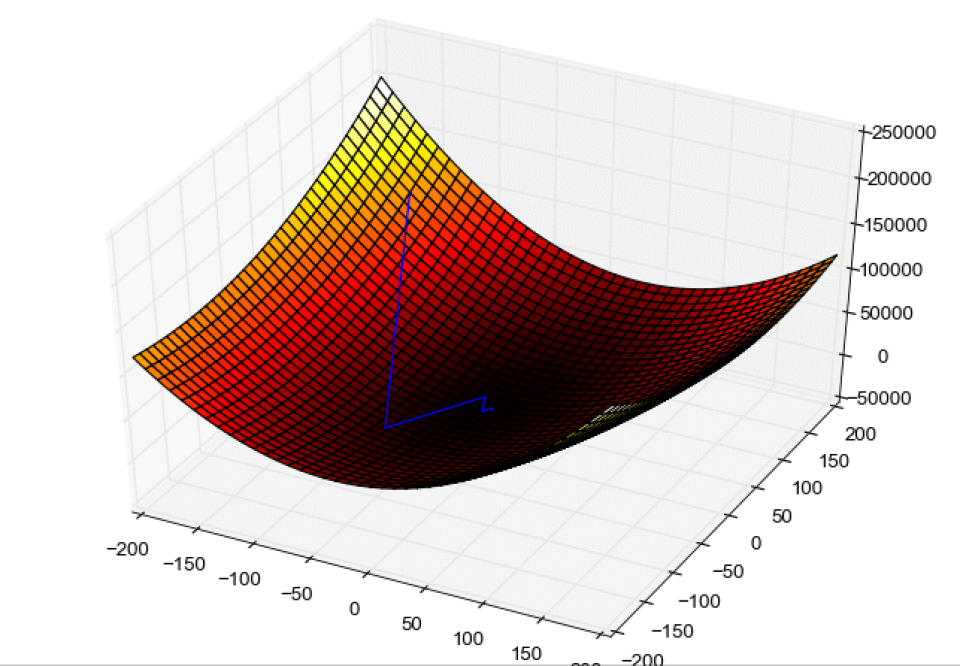
The gradient descent algorithm is represented by the blue line
In simple terms, gradient descent is a mathematical function that makes its way down to the bottom of a valley. It is a minimization algorithm meant for minimizing a given activation function.
The degree of change in the output of a function with respect to the changes made to the inputs is known as a gradient. It measures the change in all weights with respect to the change in error. A gradient can also be comprehended as the slope of a function.
12. What skills are important to become a Data Scientist?
The skills required to become a certified Data Scientist include:
- Knowledge of built-in data types including lists, tuples, sets, and related.
- Expertize in N-dimensional NumPy Arrays.
- Ability to apply Pandas Dataframes.
- Strong holdover performance in element-wise vectors.
- Knowledge of matrix operations on NumPy arrays.
13. What are the skills a Data Scientist requires, with respect to Python data analysis?
The skills required as a Data Scientist that would help in using Python for data analysis purposes are:
- Understanding Pandas Dataframes, Scikit-learn, and N-dimensional NumPy Arrays.
- Knowing how to apply element-wise vector and matrix operations on NumPy arrays.
- Understanding built-in data types, including tuples, sets, dictionaries, and so on
- Knowing Anaconda distribution and the Conda package manager
- Writing efficient list comprehensions, small, clean functions, and avoiding traditional for loops
- Knowledge of Python script and optimizing bottlenecks
14. Why is TensorFlow considered important in Data Science?
TensorFlow is considered a high priority when learning Data Science because it provides support for languages such as C++ and Python. As such, several data science processes benefit from faster compilation and completion, compared to the Keras and Torch libraries. TensorFlow also supports the CPU and GPU for faster inputs, editing, and analysis of the data.
15. What is Dropout?
Dropout is a toll in data science, which is used for dropping out hidden and visible units of a network on a random basis. They prevent overfitting of the data by dropping as much as 20% of the nodes so that the required space can be arranged for iterations needed to converge the network.
16. What are the various Machine Learning Libraries and their benefits?
The various machine learning libraries and their benefits are as follows.
- Numpy:Used for scientific computation
- Statsmodels:Used for time-series analysis
- Pandas:Used for tubular data analysis
- Scikit learns:Used for data modeling and pre-processing
- TensorFlow:Used for deep learning
- Regular Expressions:Used for text processing
- Pytorch:Used for deep learning
- NLTK:Used for text processing
17. State some Deep Learning Frameworks.
Some Deep Learning frameworks are:
- Caffe
- Keras
- TensorFlow
- Pytorch
- Chainer
- Microsoft Cognitive Toolkit
18. What is an Epoch?
Epoch in data science represents one iteration over the entire dataset. It includes everything that is applied to the learning model.
19. What is a Batch?
A batch is a series of broken-down collections of the data set, which help pass the information into the system. It is used when the developer cannot pass the entire dataset into the neural network at once.
20. What is an iteration? State an example.
An iteration is a classification of the data into different groups, applied within an epoch.
For example, when there are 50,000 images, and the batch size is 100, the Epoch will run about 500 iterations.
21. What is the cost function?
Cost functions are a tool to evaluate how good the model’s performance is. It takes into consideration the errors and losses made in the output layer during the backpropagation process. In such a case, the errors are moved backward in the neural network, and various other training functions are applied.
22. What are hyperparameters?
Hyperparameters are a kind of parameter whose value is set before the learning process so that the network training requirements can be identified and the structure of the network improved. This process includes recognizing hidden units, learning rate, and epochs, among other things.
23. What are the differences between Deep Learning and Machine Learning?
Yes, there are differences between Deep Learning and Machine Learning. These are:
|
Deep Learning |
Machine Learning |
|
It gives computers the ability to learn without being explicitly programmed |
It gives computers a limited to unlimited ability wherein nothing major can be done without getting programmed, and many things can be done without prior programming. It includes supervised, unsupervised, and reinforcement machine learning processes. |
|
It is a subcomponent of machine learning that is concerned with algorithms that are inspired by the structure and functions of human brains, called the Artificial Neural Networks |
It includes Deep Learning as one of its components |
Technical Data Science Interview Questions
24. Explain overfitting and underfitting.
In order to make reliable predictions on untrained data in machine learning and statistics, it is required to fit a model to a set of training data. Overfitting and underfitting are two of the most common modeling errors that occur while doing so.
A statistical model suffering from overfitting relates to some random error or noise in place of the underlying relationship. When a statistical model or machine learning algorithm is excessively complex, it can result in overfitting. An example of a complex model is one having too many parameters when compared to the total number of observations.
When underfitting occurs, a statistical model or machine learning algorithm fails in capturing the underlying trend of the data. Underfitting occurs when trying to fit a linear model to non-linear data.
Although both overfitting and underfitting yield poor predictive performance, the way in which each one of them does so is different. While the overfitted model overreacts to minor fluctuations in the training data, the underfit model under-reacts to even bigger fluctuations.
25. What is batch normalization?
Batch normalization is a technique through which attempts could be made to improve the performance and stability of the neural network. This can be done by normalizing the inputs in each layer so that the mean output activation remains 0 with the standard deviation at 1.
26. What do you mean by cluster sampling and systematic sampling?
Studying the target population spread throughout a wide area can become difficult. Applying simple random sampling becomes ineffective, the technique of cluster sampling is used. A cluster sample is a probability sample, in which each of the sampling units is a collection or cluster of elements.
Following the technique of systematic sampling, elements are chosen from an ordered sampling frame. The list is advanced in a circular fashion. This is done in such a way so that once the end of the list is reached, the same is progressed from the start, or top, again.
27. What are Eigenvectors and Eigenvalues?
Eigenvectors help in understanding linear transformations. They are calculated typically for a correlation or covariance matrix in data analysis. In other words, eigenvectors are those directions along which some particular linear transformation acts by compressing, flipping, or stretching.
Eigenvalues can be understood either as the strengths of the transformation in the direction of the eigenvectors or the factors by which the compressions happen.
28. What are outlier values and how do you treat them?
Outlier values, or simply outliers, are data points in statistics that don’t belong to a certain population. An outlier value is an abnormal observation that is very much different from other values belonging to the set. Not all extreme values are outlier values.
Identification of outlier values can be done by using univariate analysis, or some other graphical analysis method. Few outlier values can be assessed individually but assessing a large set of outlier values requires the substitution of the same with either the 99th or the 1st percentile values.
There are two popular ways of treating outlier values:
- To change the value so that it can be brought within a range
- To simply remove the value
29. How do you define the number of clusters in a clustering algorithm?
The primary objective of clustering is to group together similar identities in such a way that while entities within a group are similar to each other, the groups remain different from one another.
Generally, the Within Sum of Squares is used for explaining the homogeneity within a cluster. For defining the number of clusters in a clustering algorithm, WSS is plotted for a range pertaining to a number of clusters. The resultant graph is known as the Elbow Curve.
The Elbow Curve graph contains a point that represents the point post in which there aren’t any decrements in the WSS. This is known as the bending point and represents K in K–Means.
Although the aforementioned is the widely-used approach, another important approach is hierarchical clustering. In this approach, dendrograms are created first and then distinct groups are identified from there.
30. How does backpropagation work? States the variants.
Backpropagation refers to a training algorithm used for multilayer neural networks. Following the backpropagation algorithm, the error is moved from an end of the network to all weights inside the network. Doing so allows for efficient computation of the gradient.
Backpropagation works in the following way:
- Forward propagation of training data
- Output and target is used for computing derivatives
- Back propagate for computing the derivative of the error with respect to the output activation
- Using previously calculated derivatives for output generation
- Updating the weights
The following are the various variants of backpropagation:
- Batch Gradient Descent: The gradient is calculated for the complete dataset and an update is performed on each iteration
- Mini-batch Gradient Descent: Mini-batch samples are used for calculating gradient and updating parameters (a variant of the Stochastic Gradient Descent approach)
- Stochastic Gradient Descent: Only a single training example is used to calculate gradient and update parameters
31. What do you know about Autoencoders?
Autoencoders are simplistic learning networks used for transforming inputs into outputs with minimal possible error. It means that the output’s results are very close to the inputs.
A couple of layers are added between the input and the output with the size of each layer smaller than the size pertaining to the input layer. An autoencoder receives unlabeled input that is encoded for reconstructing the output.
32. Please explain the concept of a Boltzmann Machine.
A Boltzmann Machine features a simple learning algorithm that enables it to discover fascinating features representing complex regularities present in the training data. It is basically used for optimizing the quantity and weight for some given problem.
The simple learning algorithm involved in a Boltzmann Machine is very slow in networks that have many layers of feature detectors.
33. What is GAN?
The Generative Adversarial Network takes inputs from the noise vector and sends them forward to the Generator, and then to Discriminator, to identify and differentiate unique and fake inputs.
34. What are the components of GAN?
There are two vital components of GAN. These are:
- Generator: The Generator acts as a Forger, which creates fake copies
- Discriminator: The Discriminator acts as a recognizer for fake and unique (real) copies
35. What is the Computational Graph?
A computational graph is a graphical presentation that is based on TensorFlow. It has a wide network of different kinds of nodes wherein each node represents a particular mathematical operation. The edges in these nodes are called tensors. This is the reason the computational graph is called a TensorFlow of inputs. The computational graph is characterized by data flows in the form of a graph; therefore, it is also called the DataFlow Graph.
36. What are tensors?
Tensors are mathematical objects that represent the collection of higher dimensions of data inputs in the form of alphabets, numerals, and rank fed as inputs to the neural network.
37. What is the difference between Batch and Stochastic Gradient Descent?
The difference between Batch and Stochastic Gradient Descent are as follows:
|
Batch Gradient Descent |
Stochastic Gradient Descent |
|
Helps in computing the gradient using the complete data set |
Helps in computing the gradient using only a single sample |
|
Takes time to converge |
Takes less time to converge |
|
The volume is large for analysis purposes |
The volume is lower for analysis purposes |
|
Updates the weight comparatively infrequently |
Updates the weight more frequently |
38. What is an Activation function?
An Activation function helps introduce non-linearity in the neural network. This is done to help the learning process when it comes to complex functions. Without the activation function, the neural network will be unable to perform only the linear function and apply linear combinations. Activation function, therefore, offers complex functions and combinations by applying artificial neurons, which helps in delivering output based on the inputs.
39. What are vanishing gradients?
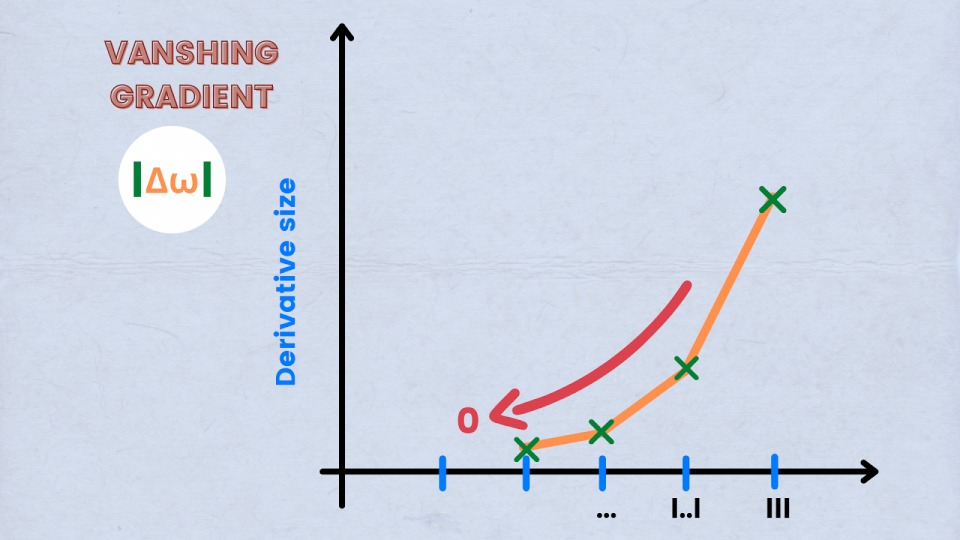
A vanishing gradient is a condition when the slope is too small during the training of Recurrent Neural Networks. The result of vanishing gradients is poor performance outcomes, low accuracy, and long-term training processes.
40. What are exploding gradients?
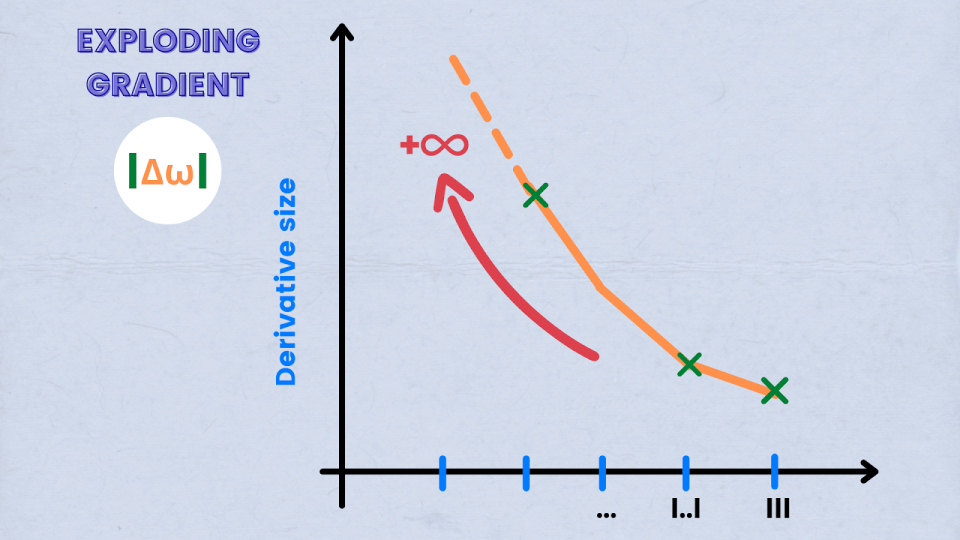
The exploding gradient is a condition when the errors grow at an exponential rate or high rate during the training of Recurrent Neural Networks. This error gradient accumulates and results in applying large updates to the neural network, causes an overflow, and results in NaN values.
41. What is the full form of LSTM? What is its function?
LSTM stands for Long Short Term Memory. It is a recurrent neural network that is capable of learning long term dependencies and recalling information for a longer period as part of its default behavior.
42. What are the different steps in LSTM?
The different steps in LSTM include the following.
- Step 1:The network helps decide what needs to be remembered and forgotten
- Step 2:The selection is made for cell state values that can be updated
- Step 3: The network decides as to what can be made as part of the current output
43. What is Pollingin CNN?
Polling is a method that is used to reduce the spatial dimensions of a CNN. It helps downsample operations for reducing dimensionality and creating pooled feature maps. Pooling in CNN helps in sliding the filter matrix over the input matrix.
44. What is RNN?
Recurrent Neural Networks are an artificial neural network that is a sequence of data, including stock markets, sequence of data including stock markets, time series, and various others. The main idea behind the RNN application is to understand the basics of the feedforward nets.
45. What are the different layers on CNN?
There are four different layers on CNN. These are:
- Convolutional Layer:In this layer, several small picture windows are created to go over the data
- ReLU Layer:This layer helps in bringing non-linearity to the network and converts the negative pixels to zero so that the output becomes a rectified feature map
- Pooling Layer:This layer reduces the dimensionality of the feature map
- Fully Connected Layer:This layer recognizes and classifies the objects in the image
46. What is an Artificial Neural Network?
Artificial Neural Networks is a specific set of algorithms that are inspired by the biological neural network meant to adapt the changes in the input so that the best output can be achieved. It helps in generating the best possible results without the need to redesign the output methods.
47. What is Ensemble learning?
Ensemble learning is a process of combining the diverse set of learners that are the individual models. It helps in improving the stability and predictive power of the model.
48. What are the different kinds of Ensemble learning?
The different kinds of ensemble learning are:
- Bagging:It implements simple learners on one small population and takes mean for estimation purposes
- Boosting:It adjusts the weight of the observation and thereby classifies the population in different sets before the outcome prediction is made
The Bottom Line
That completes the list of the top data science interview questions. This list is by no means exhaustive, and we urge you to do more of your study — particularly for data science technical interview questions.
Taking some of the best data science courses and tutorials will also help. Udemy’s Data Science Career Guide - Interview Preparation is particularly useful for interview prep. We also suggest to you Practical Statistics for Data Scientists: 50 Essential Concepts 1st Edition, one of the best books on the subject.
People are also reading:
- Difference between Data Science vs Data Analytics
- Difference between Data Analyst vs Data Scientist
- Best Data Science Books
- Best Data Analytics Courses
- Top Python Data Science Libraries
- What is Data Analysis?
- What is Data Analytics?
- Difference between Data Science vs Machine Learning
